How to build your own ChatGPT with Ollama

Introduction
Most of the AI services out there consists of pretty similar parts. You have a frontend, a backend, a database and a machine learning model. In this guide we will show you how to setup a ChatGPT style service with:
- Ollama Web UI - frontend. We have forked it into a separate branch and added some customizations to implement monetization (users can see their current balance and pay for the service).
- Ollama and Lightning AI - our AI model deployed on an A10G GPU.
- Meteron - our storage and billing service.
Web UI
Web UI's fork of Ollama Web UI is available on GitHub here.
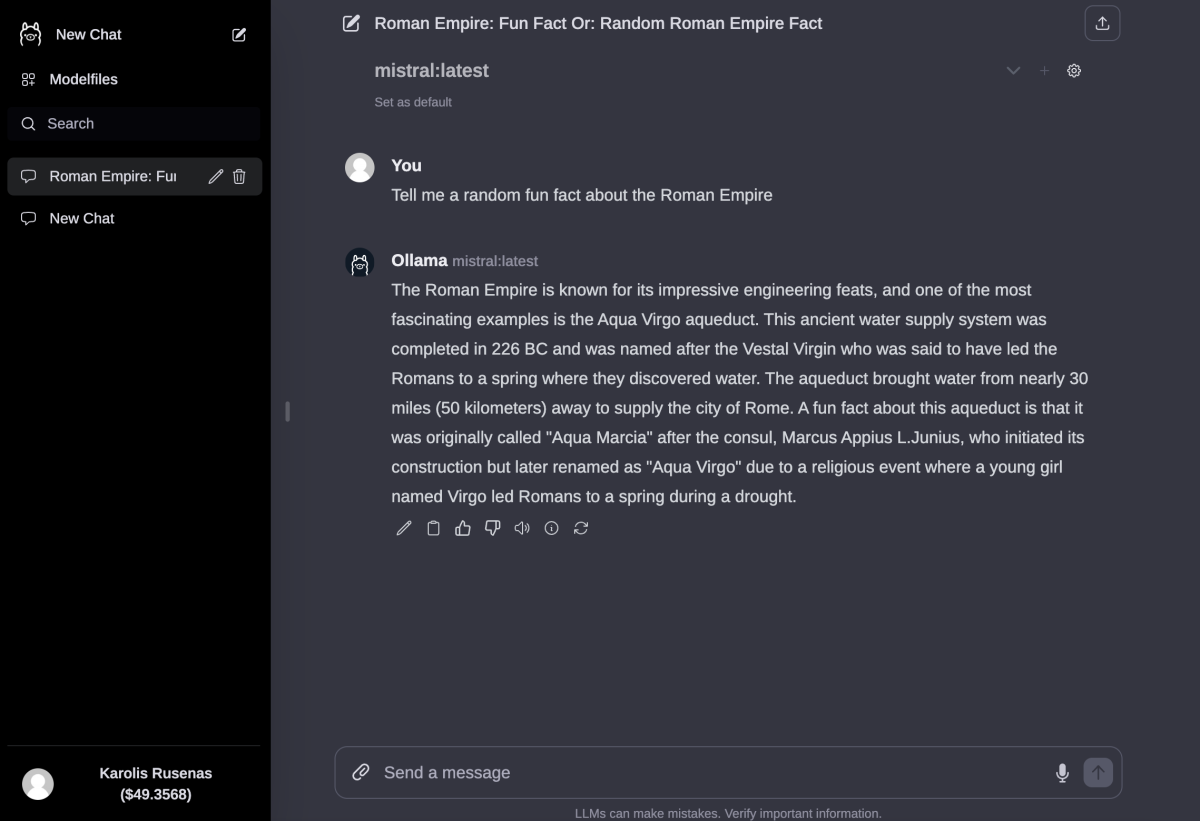
Main differences from the original Ollama Web UI that you would need to implement for monetization are:
Initial credits for new users
This step is optional but if your service provides some initial credits to new users, right after they sign up, give credits:
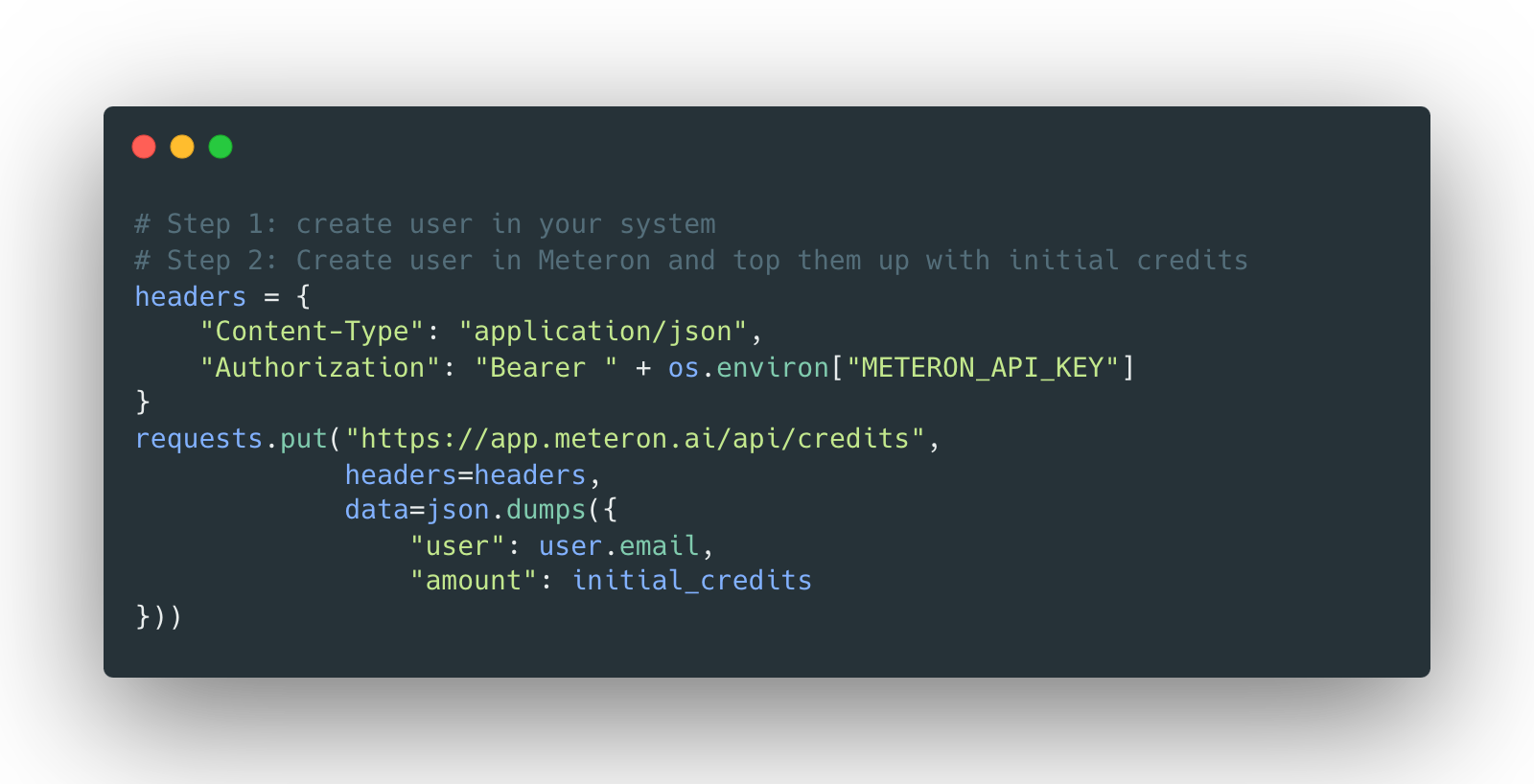
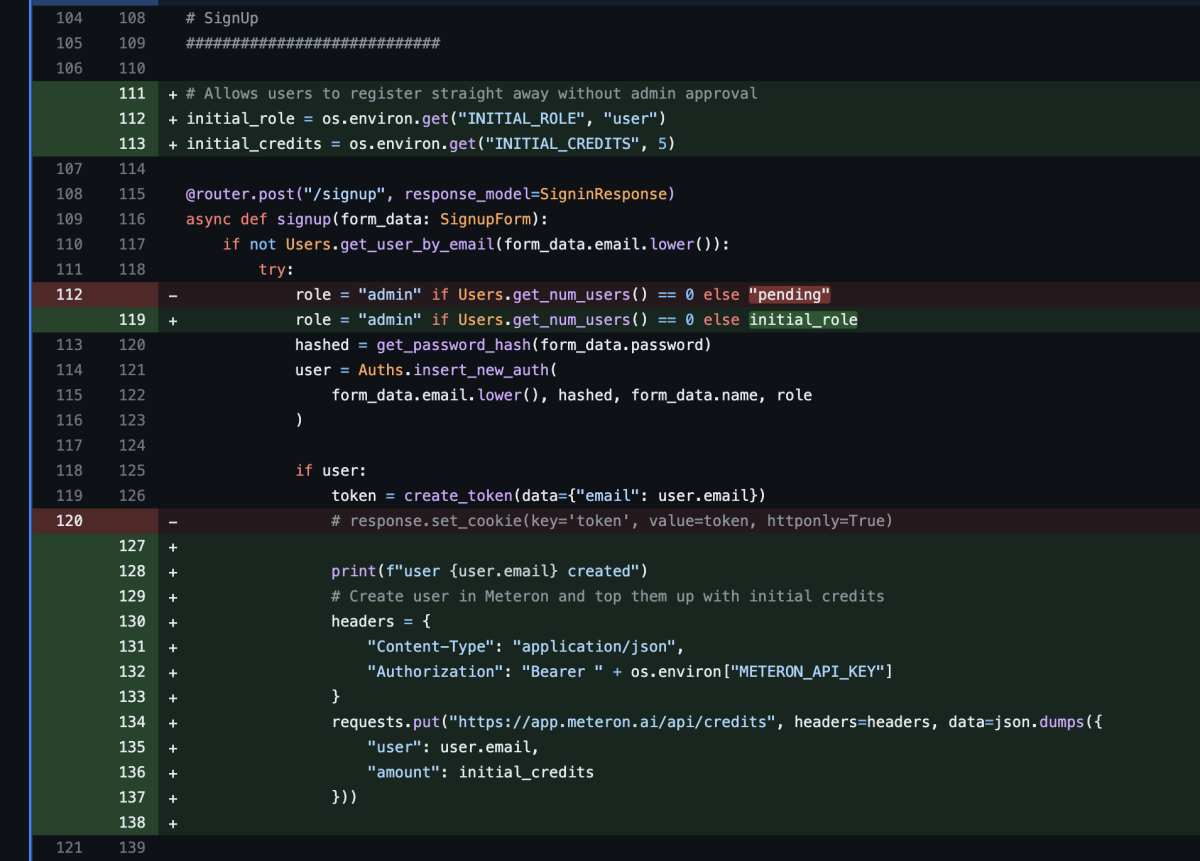
Insert this code right after the user creation:
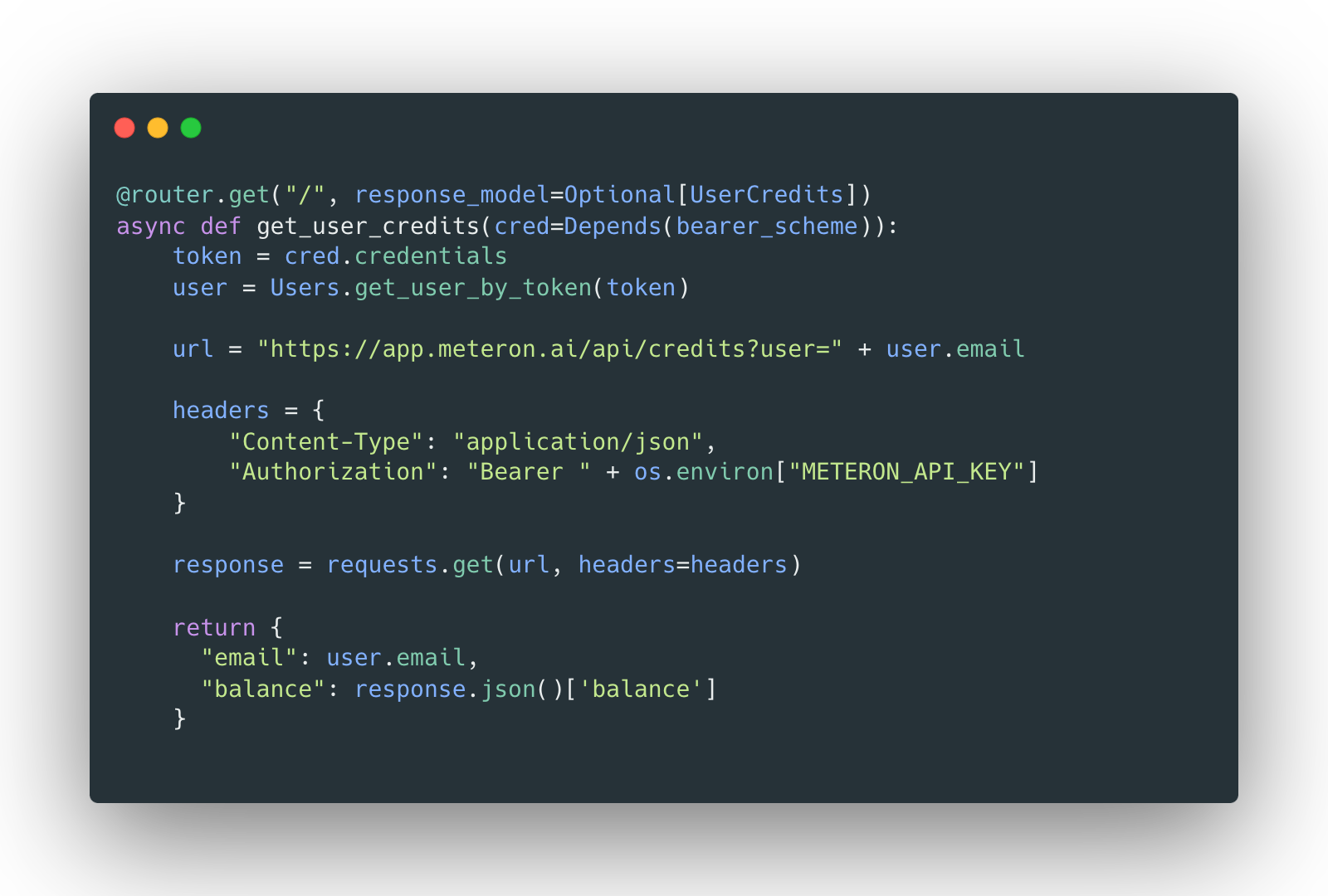
Displaying user's balance
Users need to see their balance. To get current balance, we use Meteron's API. We have added a new /credits/ endpoint to the backend:
Top-ups work through Stripe integration. On /checkout-session endpoint we create a new checkout session and return the URL to the client.
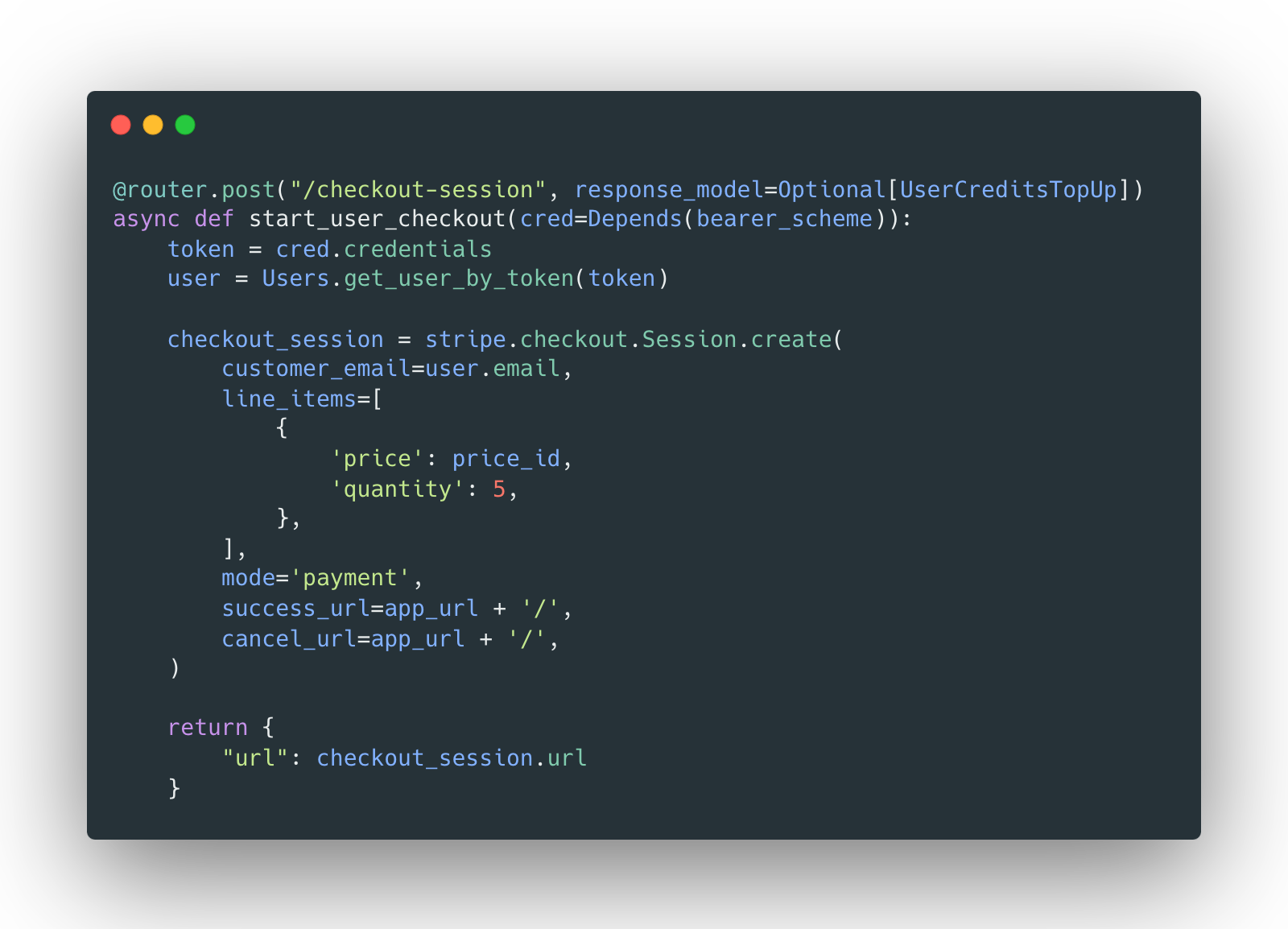
Once the checkout session is created, the user is redirected to the Stripe checkout page where they can pay for the service. Once paid, a Stripe webhook is sent to the backend:
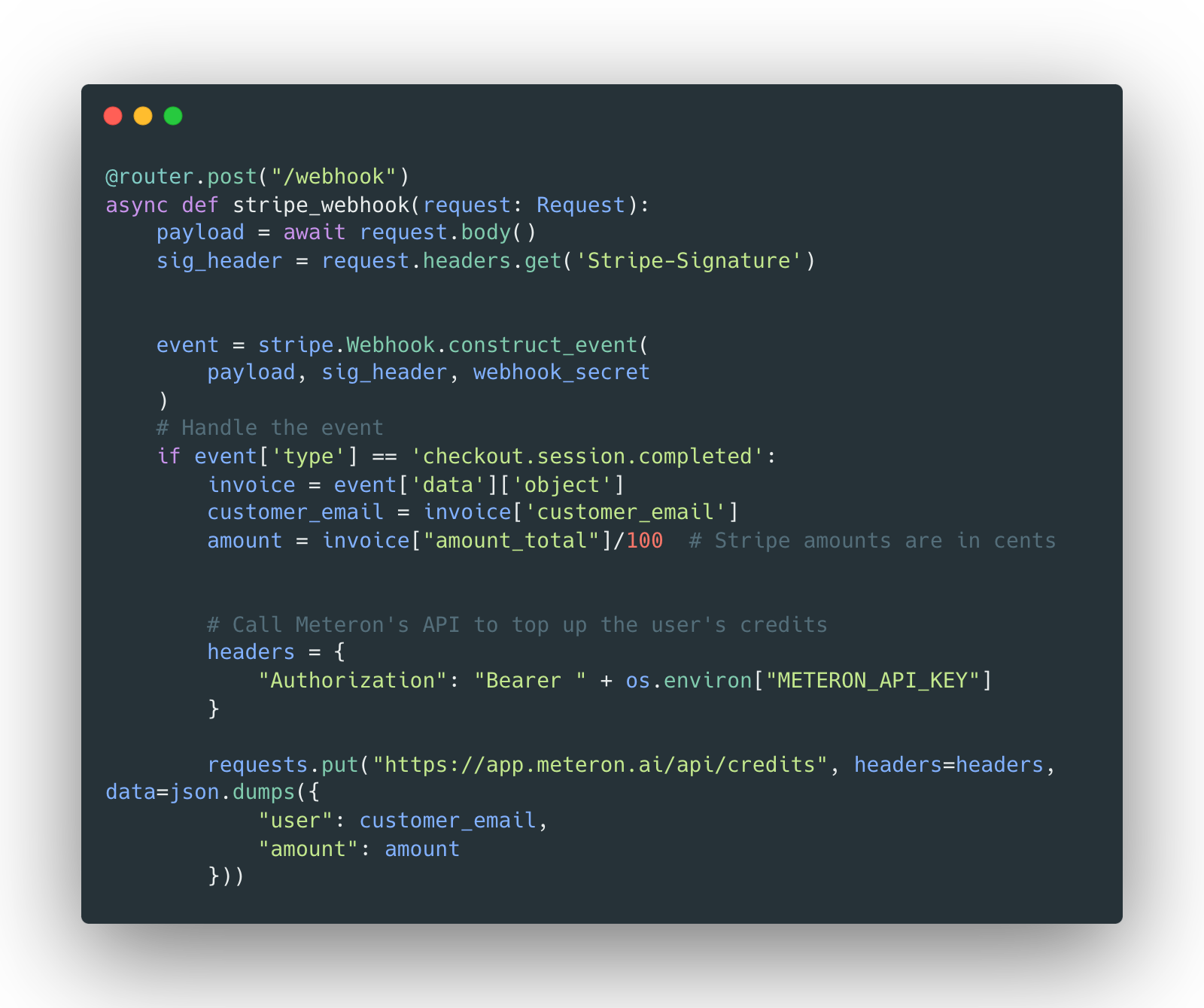
You can find all the source code here: https://github.com/meteron-ai/ollama-webui/blob/accf0cd6d3257807a9e3178428d69c359a6826b9/backend/apps/web/routers/credits.py.
Setting up the model
For running the model we use Lightning AI. Head over to their website and create an account. Once you have an account, start a new studio, switch to A10G machine and start an Ollama endpoint.
You can find instructions on running the server here:
Setting up prices and billing for your AI app
Once you have your model running, go to https://app.meteron.ai and create a new model:
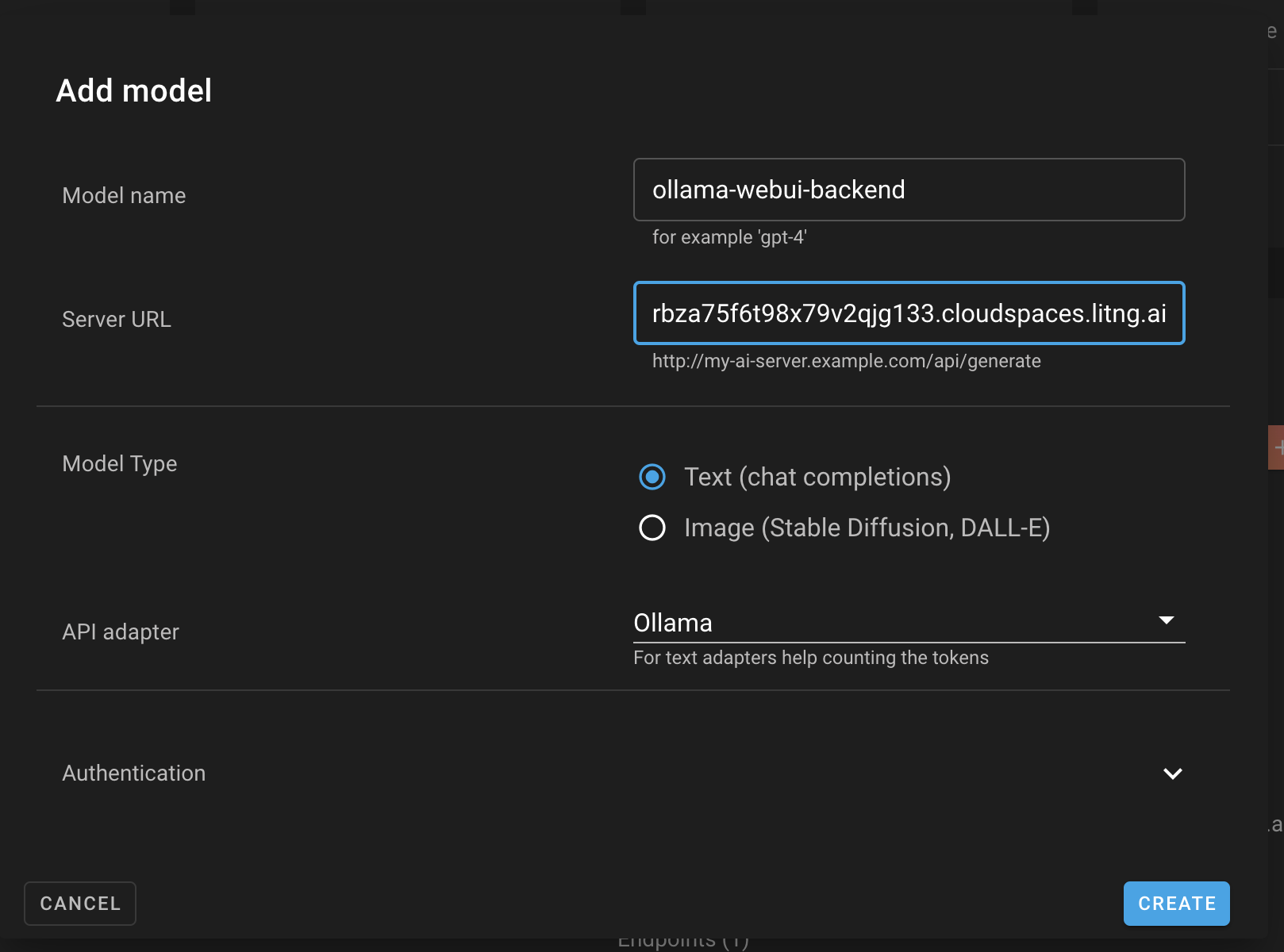
The important bits here are:
- Do add the URL like
https://11434-******.cloudspaces.litng.aiand nothttps://11434-******.cloudspaces.litng.ai/api/generateor/api/chat. Web UI needs other paths too to get available models. Meteron proxies them transparently. - If you model has authentication, enable it in Meteron too.
- Do not include the private Meteron API key in your frontend. It is only needed in your backend.
Enable the "Monetization" section and optionally "User usage limits":
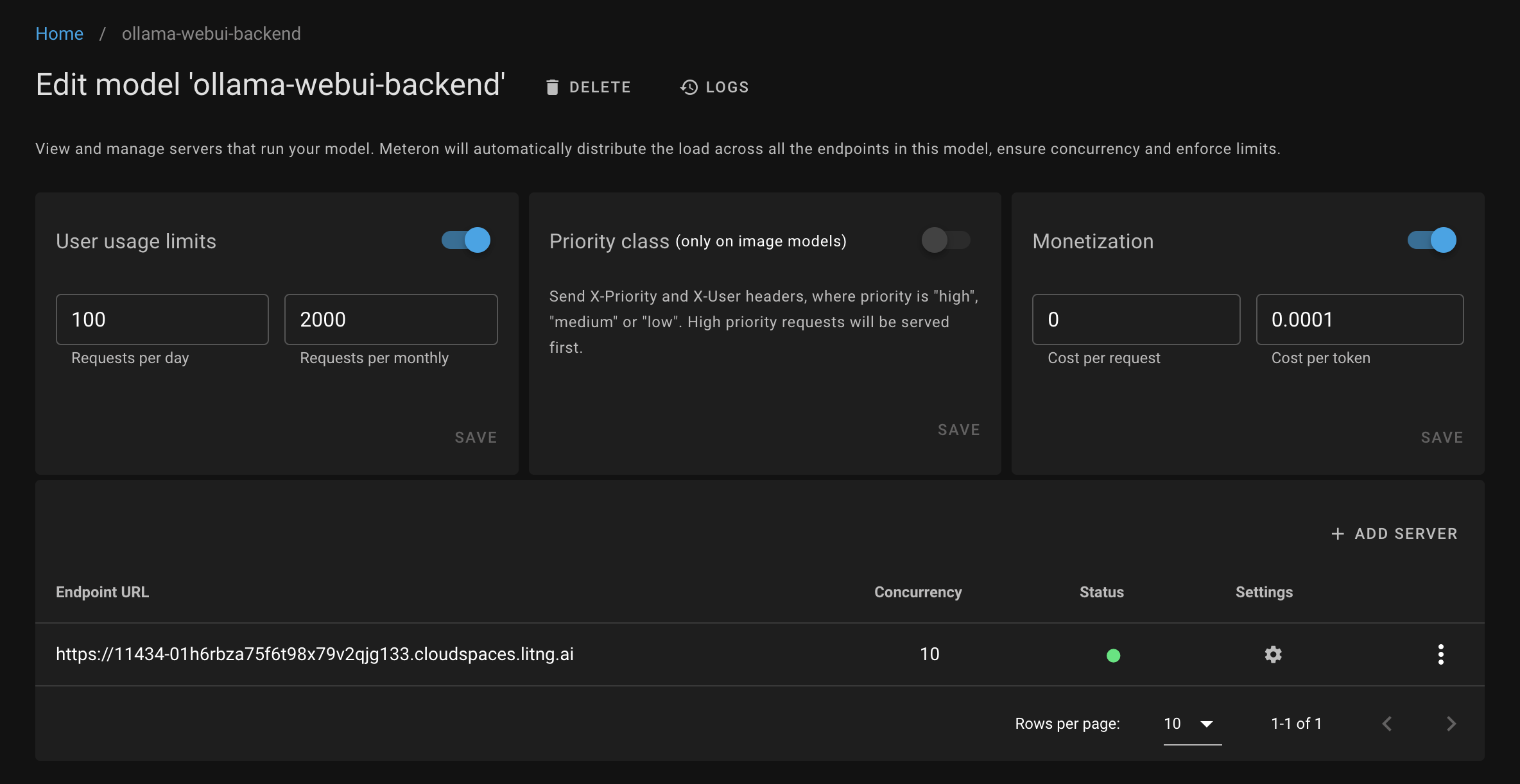
Once added, you can try calling the chat endpoint using the generator helper:
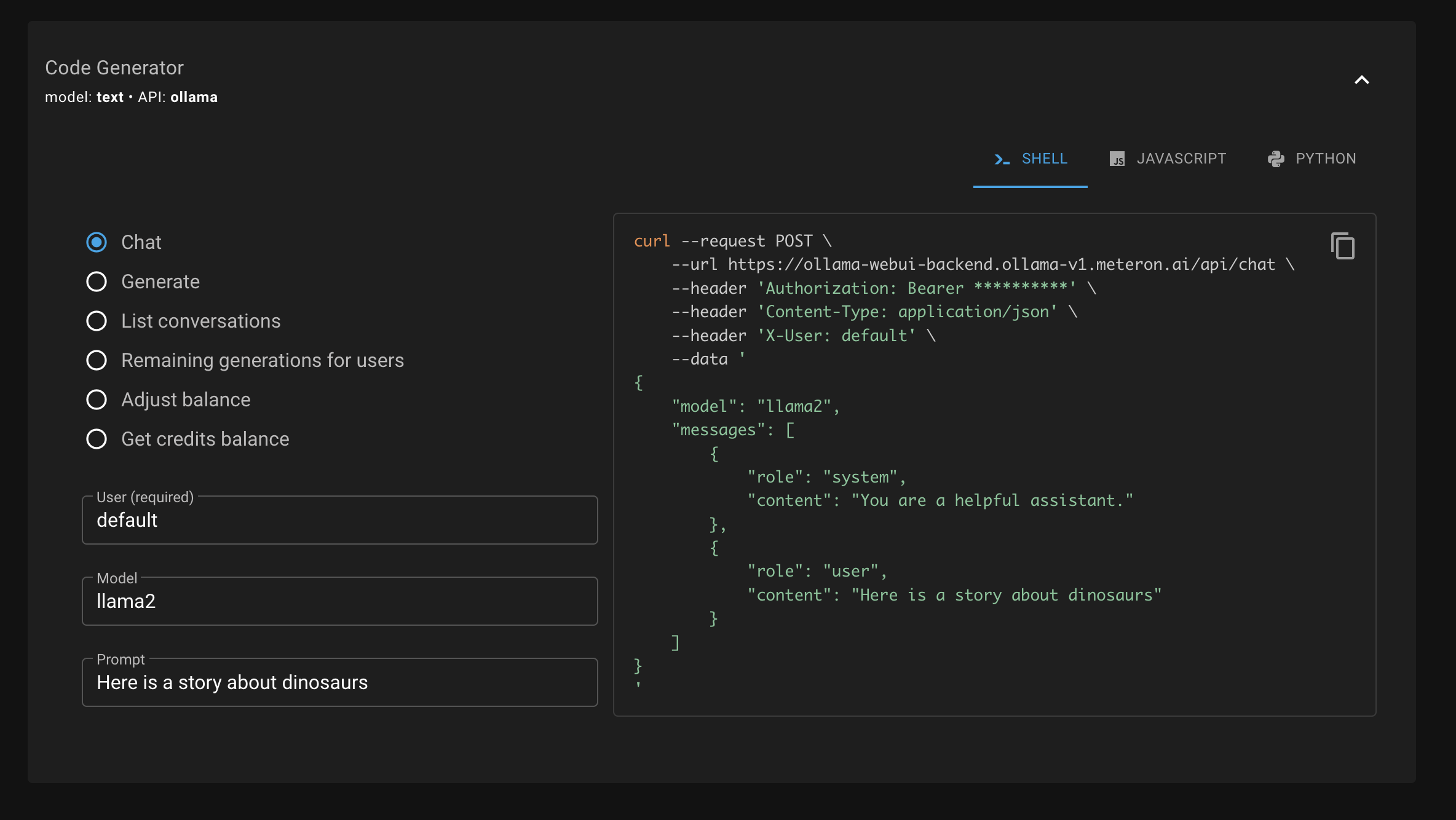
This makes an API call where Meteron will count the tokens used and deduct the credits from the user's balance. If the user doesn't have enough credits, the API call will fail with an error.
In the model logs page you can see all the API calls made to your model, their inputs, outputs and tokens used.
Using Meteron APIs to charge users
After adding the model to Meteron, switch your backend and frontend application to use Meteron API instead of your model directly.
For example if your model is running on https://11434-******.cloudspaces.litng.ai and your model endpoint in Meteron is https://ollama-webui-backend.ollama-v1.meteron.ai then all calls to your model should be made to https://ollama-webui-backend.ollama-v1.meteron.ai/api/chat instead of https://11434-******.cloudspaces.litng.ai/api/chat.
Set up Authorization headers to authenticate with Meteron.
Connecting it all together
I have created a Docker Compose file that you can try out locally. It will start the backend that can serve frontend and will proxy API calls to Meteron instead of Ollama server. You can find it here on Github.
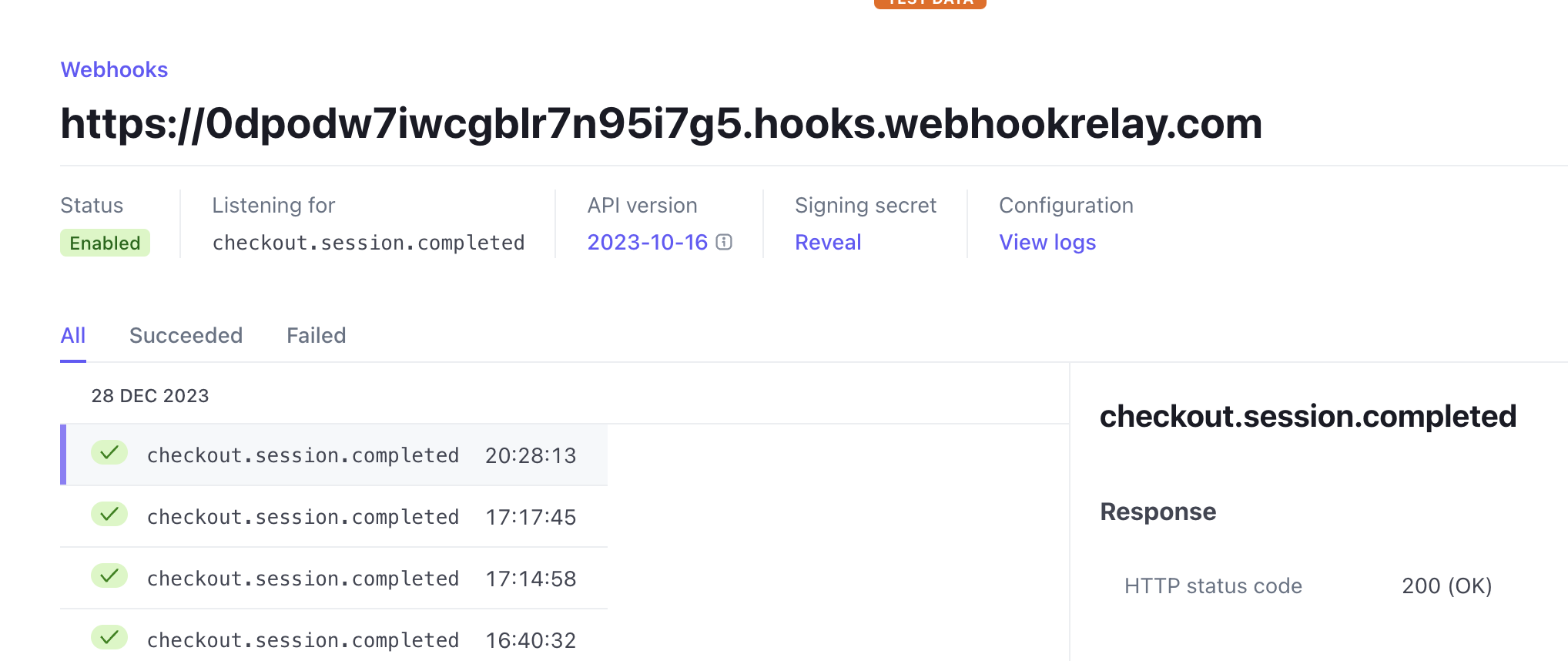
To test Stripe top-ups locally, use Webhook Relay:
relay forward -b chat-stripe http://localhost:8888/api/v1/credits/webhookAnd then configure a checkout.session.completed webhook in your Stripe dashboard:
Troubleshooting
Things to check when building your own AI service:
- Make sure your AI model is running and you can make API calls to it directly.
- Make sure the API calls to your model are proxied through Meteron and correct API type is set. If you are using OpenAI style models (OpenAI, vLLM, etc.) you should pick it from the menu when adding the model.
- Make sure you have set up the correct Authorization headers in your backend.
- Check if your frontend supports streaming API calls. If not, it's easier to start with streaming disabled and then turn it on later on. Meteron can proxy both streaming and non-streaming API calls.