How to server AI models at scale?
Tired of your AI system crashing due to server overload?

Are you struggling with managing your storage capacity for your AI images? Look no further than Meteron, the solution to all your problems.
With Meteron, you no longer have to worry about server crashes because it uses a queueing system that ensures good utilization of server resources. This means that all requests to your AI system will be handled in an orderly and efficient manner, preventing any potential crashes. This does wonders with CPU, GPU and RAM utilization problems.
Challenges of running AI systems
There are many issues that can arise when running an AI system. Most of the "Hello World" apps don't have to worry about server over-utilization, storage and user limits. But as soon as you start planning to deploy your product, you will have to deal with these issues.
Here’s what we discovered:
- Queuing and load-balancing for your inference servers.
- Prioritization.
- Collecting the artifacts and putting them into cost-efficient cloud storage.
- Per-user limits for fair use or enabling monetization.
Meteron attempts to address all of these issues in a single platform. It is a complete solution for using your AI models in production.
1. Queueing and load balancing
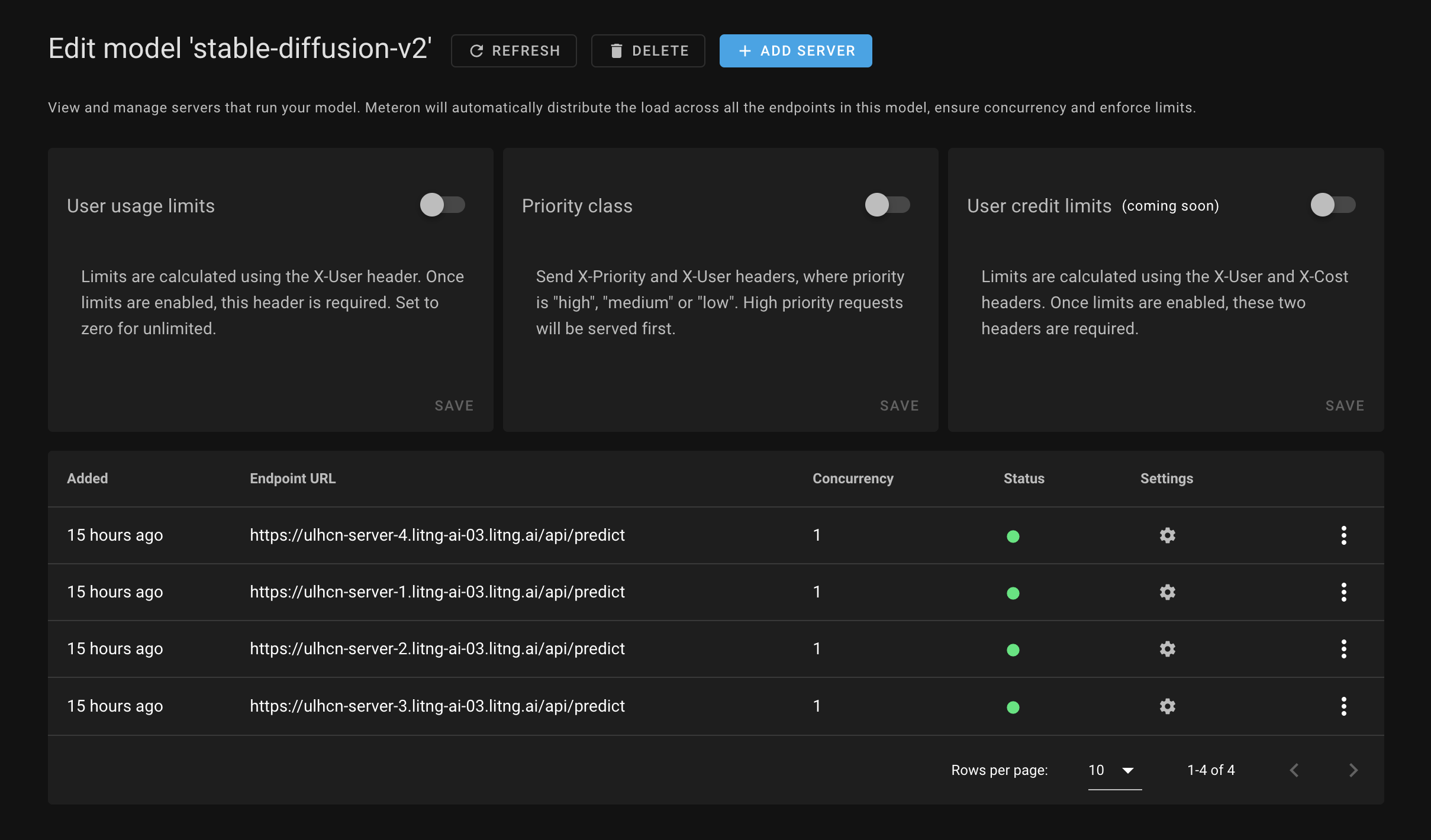
With Meteron, you no longer have to worry about server crashes because it uses a queueing system that ensures good utilization of server resources. This means that all requests to your AI system will be handled in an orderly and efficient manner, preventing any potential crashes.
2. Prioritization
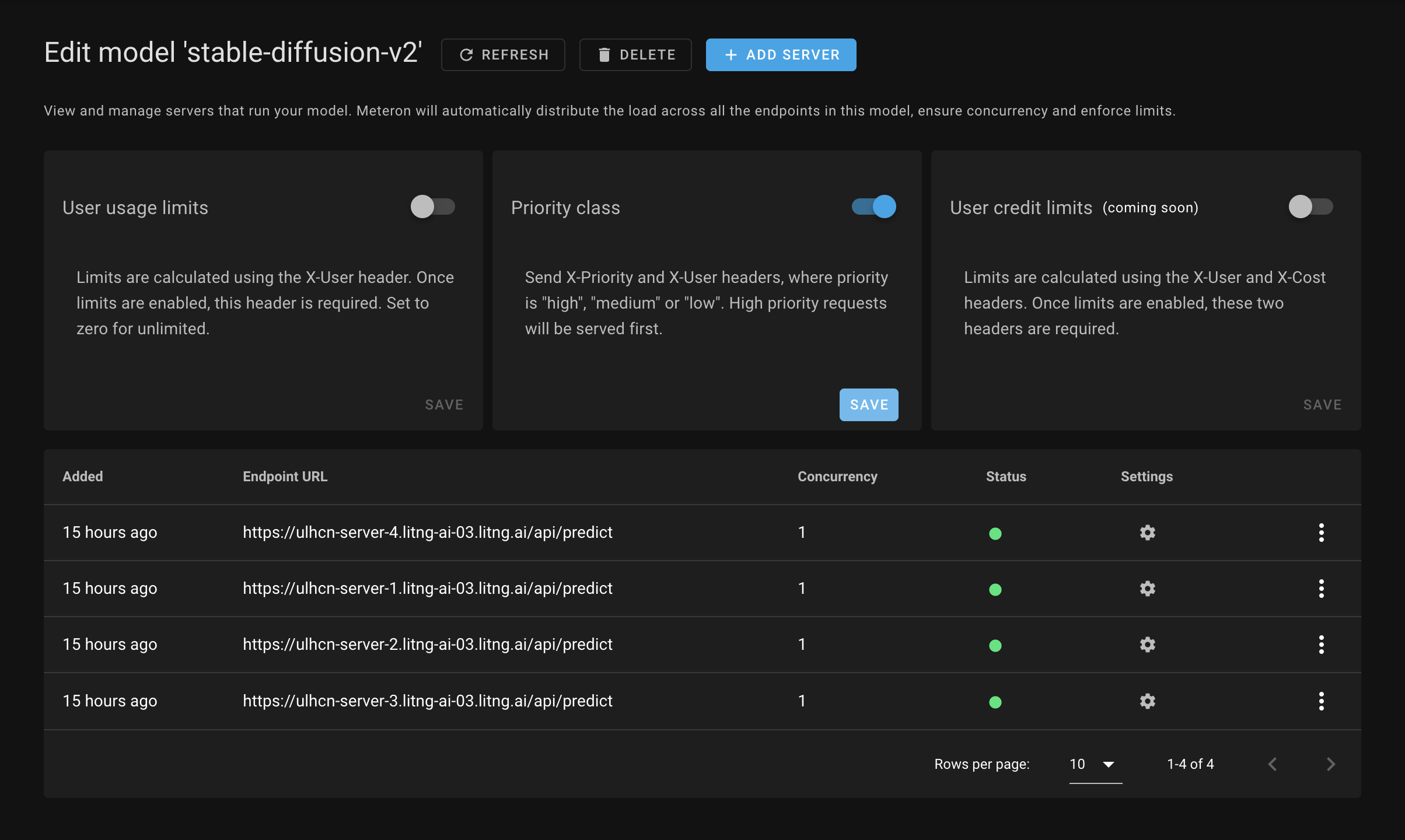
Meteron allows you to separate requests into three different classes:
- High - these requests will be processed first
- Medium - processed after 'high' priority requests are done but optionally gets reduced priority if the user is making a lot of requests
- Low - processed once there are no high or medium priority requests
This model allows you to have a flexible system that can be used for a variety of use cases. For example, you can use it to prioritize requests from paying customers over free users.
3. Artifact cloud storage
All model outputs are automatically uploaded to a cloud object store such as AWS S3, GCP Google Cloud Storage, Cloudflare R2, etc. You can add your own cloud credentials to Meteron to use your storage. By default we use Cloudflare R2 and provide you with the presigned URLs to download the assets. You will never have to think about running out of storage.
4. User daily/monthly limits and credits
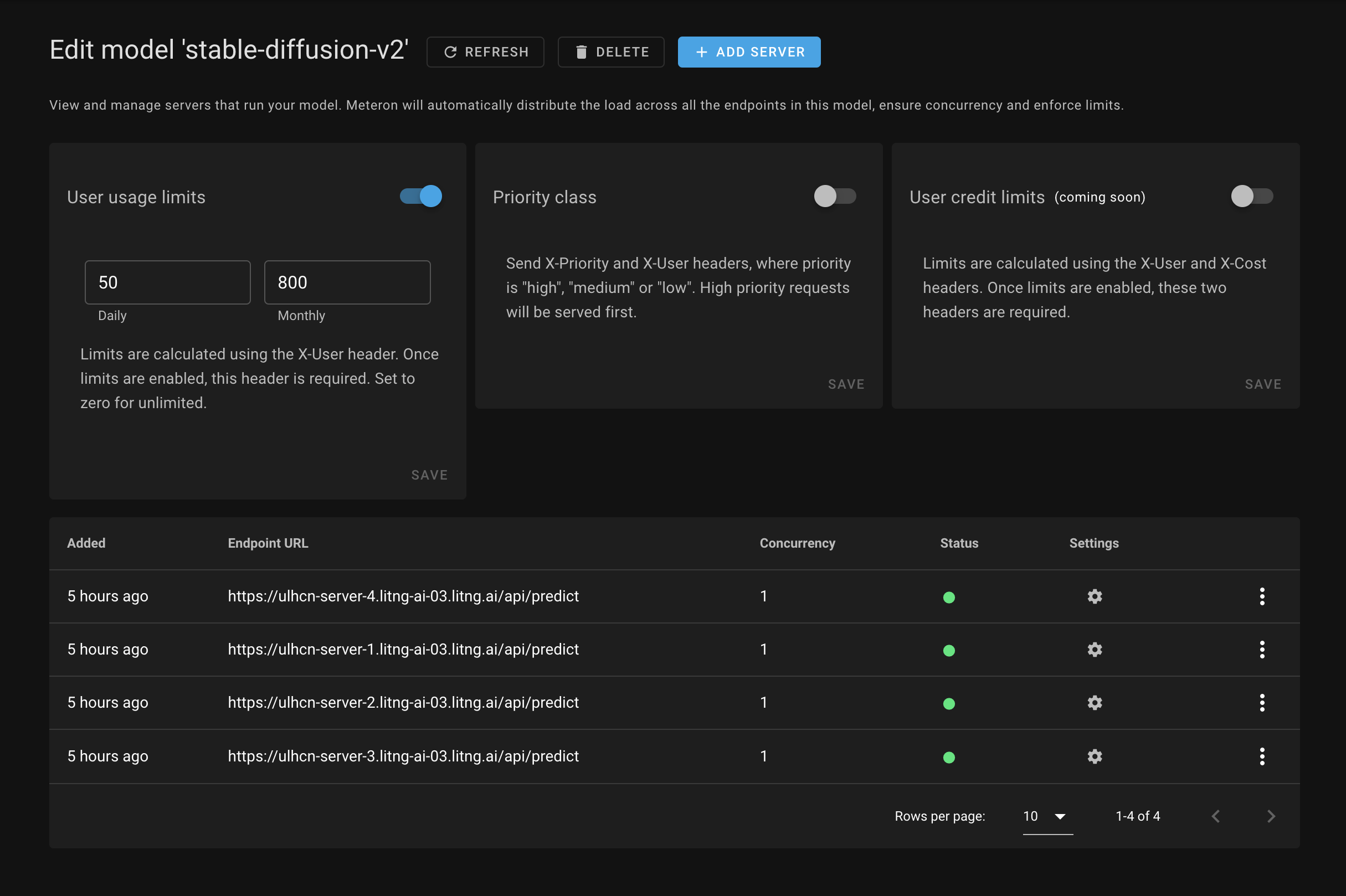
Finally, Meteron allows you to set limits per user, making it easy to build AI-backed SaaS apps. With this feature, you can set usage limits and pricing tiers, ensuring that your users are getting the most out of your AI system while you maintain control over usage and costs.
Conclusions
As you can see, Meteron provides the solutions to the hard problems when building AI products. Check out our other guides on specific features of Meteron to learn about prioritization, limits, artifacts and more.